








;)
;)
;)





오픈 데이터셋 '커먼 파일' 공개
오픈 라이선스 콘텐츠만 선별 사용
AI 학습에서 '저작권 논란' 제거
메타 '라마2'와 비슷한 성능 확인
오픈 라이선스 콘텐츠만 선별 사용
AI 학습에서 '저작권 논란' 제거
메타 '라마2'와 비슷한 성능 확인
 이미지 확대보기
이미지 확대보기
AI 개발의 투명성과 저작권 논란이 첨예하게 대두된 가운데, 전 세계 연구진이 협력해 만든 대형 오픈 데이터셋 '커먼 파일(Common Pile)'이 8TB(테라바이트) 규모로 공개됐다. 이번 프로젝트는 AI 업계가 저작권 침해 우려로 데이터 비공개 기조를 강화하는 상황에서, '공정하고 투명한 AI 생태계' 구축에 새로운 해법을 제시했다는 평가를 받고 있다.
'커먼 파일 v0.1'은 엘레우테르AI(EleutherAI), 토론토대, 허깅 페이스(Hugging Face), 알렌인공지능연구소(Allen Institute for AI) 등 글로벌 연구진이 공동 개발했다. 이 데이터셋은 퍼블릭 도메인과 CC BY, CC BY-SA, CC0, MIT, BSD 등 오픈 라이선스 콘텐츠만을 엄격히 선별해 구성됐으며, 상업적 이용 금지(CC NC)나 변형 금지(CC ND) 등 제한적 라이선스 자료는 포함하지 않았다.
업계에서는 저작권 논란을 피하면서도 누구나 자유롭게 활용할 수 있는 데이터셋이 공개된 것은 이례적이라는 평가가 나온다.
 이미지 확대보기
이미지 확대보기
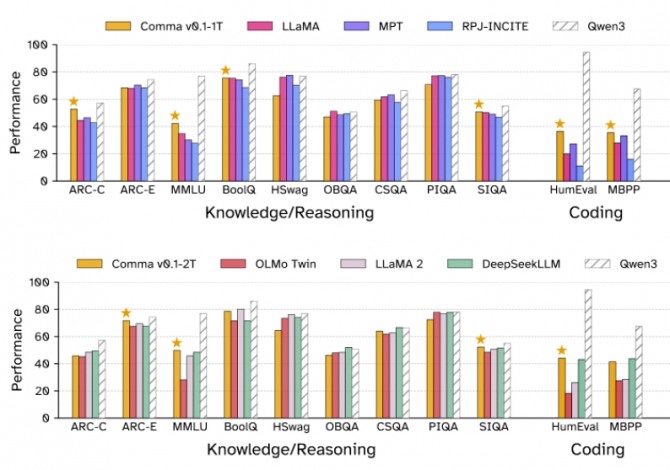
이번 커먼 파일로 학습된 70억 파라미터 언어모델 'Comma v0.1'은 메타(Meta)의 라마 2(Llama 2) 등 기존 고성능 모델과 맞먹는 성능을 기록했다. 특히 학술 논문, 소스코드 등 고품질 데이터가 풍부해 전문지식·프로그래밍 분야에서 강점을 보였으며, 일부 일상 상식 분야에서는 기존 모델에 다소 뒤처졌지만 전체적으로 "오픈 데이터만으로도 경쟁력 있는 AI 개발이 가능하다"는 점을 입증했다.
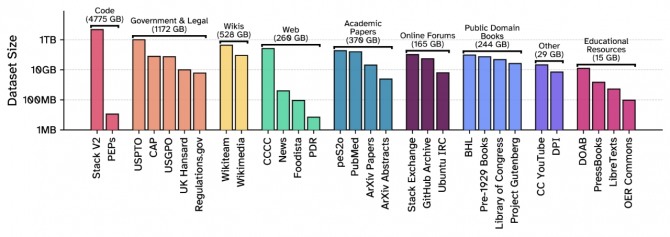
커먼 파일은 30여 개의 다양한 소스에서 8TB 분량의 데이터를 수집했다. 여기에는 오픈소스 소프트웨어(4.7TB 이상), 정부·법률 문서(1.1TB 이상), 학술 논문, 공공 도메인 도서, 온라인 포럼, 2000여 유튜브 채널 자막, 위키피디아 등 방대한 자료가 포함됐다.
양질의 데이터를 얻기 위해 신뢰성 낮은 데이터, 중복·저품질·유해 콘텐츠, 개인정보(Personally Identifiable Information) 등은 다단계 필터링과 익명화로 엄격히 배제했으며, 각 소스별 품질에 따라 학습 비중을 조정하는 '데이터 믹싱' 전략도 적용됐다.
최근 AI 기업들이 저작권 소송을 우려해 데이터 내역을 비공개로 전환하는 가운데, 커먼 파일은 법적·윤리적 정당성을 최우선으로 하면서도 고품질 데이터를 누구나 자유롭게 쓸 수 있도록 해, 업계 투명성 제고에 기여할 것으로 기대된다.
연구진은 앞으로 도서관, 박물관, 공공기관 등과 협력해 문화유산·고문서 등으로 데이터셋을 확장할 계획이다.
이상훈 글로벌이코노믹 기자 sanghoon@g-enews.com






















