;)
;)





손재주 특화 파운데이션 모델, RoboCasa 평가 VLA 최초 70점 돌파
호텔·물류 현장 인간 동작 데이터 학습…국내 대기업·일본 기업과 개념검증 착수
호텔·물류 현장 인간 동작 데이터 학습…국내 대기업·일본 기업과 개념검증 착수
 이미지 확대보기
이미지 확대보기
서울 소재 스타트업 RLWRLD가 독자 개발한 로봇 파운데이션 모델 RLDX-1이 엔비디아, 피지컬 인텔리전스 등 세계 최고 수준의 경쟁 모델을 글로벌 8개 벤치마크에서 모두 제쳤다.
다섯 손가락 로봇 손의 정교한 물체 조작이라는 산업 현장의 오랜 난제를 풀었다는 평가와 함께, 호텔·물류·유통 현장에서 직접 수집한 인간 동작 데이터를 학습에 활용하는 방식도 주목받고 있다.
SK텔레콤·LG전자·CJ대한통운 등 국내 대기업과의 개념검증도 이미 시작됐다.
피지컬 인텔리전스는 구글 딥마인드 출신 연구진이 주축이 돼 설립한 미국 샌프란시스코 소재 로봇 AI 스타트업으로, π0·π0.5는 다양한 로봇 하드웨어에서 작동하도록 설계된 이 회사의 대표 파운데이션 모델이다.
RLDX-1의 기술 핵심: 네 가지 감각을 동시에 처리
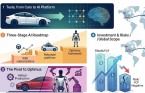
기존 시각-언어-행동(VLA) 모델들은 영상과 언어 신호를 단일 처리 흐름에 합쳐 넣어, 어느 한 정보가 학습 용량을 독점하는 구조적 한계를 안고 있었다. RLWRLD는 이를 극복하고자 '다중 스트림 행동 변환기(Multi-Stream Action Transformer·MSAT)'를 독자 설계했다.
MSAT는 영상·동작·기억·토크 신호 각각에 별도 처리 흐름을 부여한 다음, 공동 자기 주의(joint self-attention) 방식으로 융합해 행동을 생성한다.
여기에 세 가지 전용 모듈이 결합된다. '물리 모듈(Physics Module)'은 손목 토크와 촉각 피드백을 실시간으로 읽어, 커피포트가 가벼워지는 순간처럼 시각으로 포착할 수 없는 접촉 변화를 감지한다.
'동작 모듈(Motion Module)'은 이동하는 컨베이어벨트 물체를 놓치지 않도록 여러 프레임에서 시공간 대응 관계를 추출한다.
'인지 인터페이스(Cognition Interface)'는 64개 학습 토큰으로 시각-언어 모델 출력을 압축해 장기 기억 캐시에 저장하고, 이전 단계를 기억하며 다음 행동을 결정한다. 이 구조 덕분에 추론 속도가 16.3㎐에서 22.1㎐로 35% 높아졌다고 RLWRLD는 설명했다.
벤치마크 결과를 보면, 부엌 작업 평가인 RoboCasa에서 VLA 모델 최초로 70점을 넘는 70.6점을 기록했다. 휴머노이드 로봇 전용 GR-1 Tabletop 평가에서는 58.7점으로 엔비디아 GR00T N1.6보다 10.7%포인트 높았다.
조명·카메라 각도 등 7개 변수를 종합하는 LIBERO-Plus에서는 86.7%를 받았다. WIRobotics의 ALLEX 휴머노이드로 진행한 실물 '포트-투-컵 따르기' 실험에서는 70.8%의 성공률을 보여, 경쟁 모델들의 30%대 후반과 뚜렷한 차이를 냈다.
현장 데이터에서 시작한 상용화 전략
RLWRLD의 차별점은 기술 구조에서만 나오지 않는다. 롯데호텔 서울 직원들이 연회용 냅킨을 접고 테이블을 차리는 장면, CJ대한통운 물류센터의 작업 동선, 편의점 로손(Lawson)의 진열 과정을 체장 카메라로 촬영해 훈련 데이터로 전환하고 있다.
사람의 손이 실제로 어떻게 쥐고, 얼마나 힘을 주고, 어떤 순서로 움직이는지를 고해상도로 포착하겠다는 것이다.
학습 데이터 부족은 합성 데이터 엔진으로 보완한다. 영상 생성 모델 'Cosmos-Predict2'로 조명·배경·물체 위치를 달리한 새 동작 영상을 대량으로 만들어, 실제 시연 대비 약 5배 규모로 데이터를 늘렸다.
이를 통해 GR-1 Tabletop 벤치마크에서 평균 성공률이 9.2%포인트 높아졌다고 RLWRLD는 밝혔다.
RLDX-1은 81억 개 매개변수(파라미터) 규모의 3개 버전이 깃허브(GitHub)·허깅페이스(Hugging Face)를 통해 외부 연구자에게 공개됐다.
SK텔레콤·LG전자·CJ대한통운·롯데, 일본의 KDDI·ANA홀딩스·미쓰이화학·시마즈 등과는 개념검증(PoC) 프로젝트도 시작했다고 회사 측은 전했다.
한국 정부도 숙련 기술자의 노하우를 AI 데이터베이스로 구축하는 약 330억 원(미국 달러 기준 약 2210만 달러) 규모 국책 사업을 착수했다.
업계에서는 고령화·인구 감소로 인한 제조 현장 인력난을 로봇으로 채우려는 정책 방향이 피지컬 AI 기업의 상용화를 앞당길 것으로 보고 있다.
RLWRLD는 접촉·토크·로봇 상태 정보를 시간 축으로 시뮬레이션하는 '4D+ 세계 모델' 개발을 다음 목표로 제시했다.
진형근 글로벌이코노믹 기자 jinwook@g-enews.com